RenderGraph是什么?
如果我们把渲染过程想象成BipartiteGraph(二分图),关于二分图与其它有向图的参考可点击该链接。
这意味着有两个元素集合,其中一个集合的元素只能与另一个集合的元素相连, 以延迟管线为例:
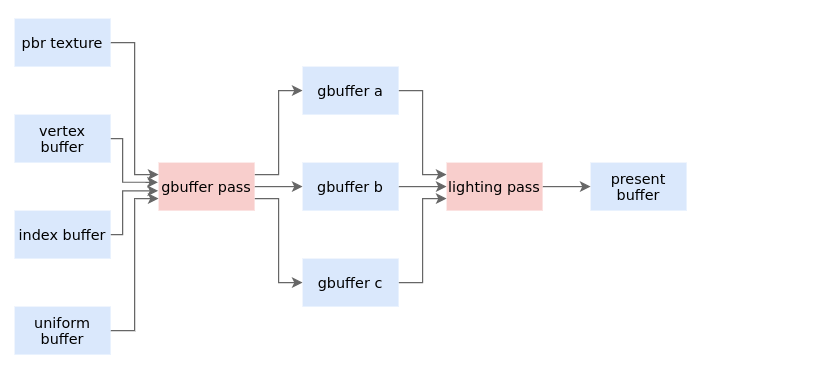
浅蓝色为资源,浅红色为通道
以整个延迟管线渲染过程来说明,这两个集合可以被拆分为resources(资源)与passes(通道)。passes会利用所提供的resources执行相应的着色器走光栅化的流程(即drawcall),整个drawcall会有特定的PipelineState(即管线状态),PipelineState是指混合方式、是否深度测试、视口大小、面剔除等一系列状态信息。同时,Passes也会产生资源,比如Buffers与Framebuffer等。
上述过程即是一个基本的RenderGraph流程。
Immediate mode vs retained mode
现代GPU渲染API(如Vulkan、Metal或DirectX 12)暴露了更多底层的API接口,更多的接口对于图形开发人员就意味着更复杂,也意味着要管理的东西就越多,这与图形开发人员希望所写的代码能够立即产生输出结果的开发习惯相违背。如果编写过Vulkan,Metal或DX12,会发现这些现代的GPU API往往需要先提前设定好或加载好所有需要的东西,最后才去执行它们,还是以设定PipelineState为例:我们需要提前设定帧缓存,光栅化状态,InputAssembler状态,Blend状态等,再通过CommandBuffer组织RenderPass的一系列渲染逻辑,所有的准备工作只为了最后的渲染做准备。如果把现代GPU API的这类操作称为RetainedMode(保留模式)的话,那么开发人员(虽然个人代表不了所有人)就更偏向于ImmediateMode(立即模式,传统的Opengl API就比较偏向于该模式)。所以RenderGraph的产生就能够调和这两种模式的矛盾。
Graph declaration, invocation, and dispatch
要创建一个RenderGraph一般可以归纳为以下三个步骤:
Declaration(声明): 在这个步骤,我们可以添加Pass与Resource,并对即将渲染的每个Pass指定管线状态。
Invocation(调用): 在这个步骤会去调用Pass的begin()/end()函数,由于在Declaration(声明)阶段已经组织好了Pass的相关数据,所以在调用Pass的begin()/end()函数时RenderGraph能够知道如何做出相应处理,并可以对其进行优化。
Dispatch(派发):这个步骤会真正执行对应DrawCall或ComputeShader,但是RenderGraph不需要知道也不用关心这部分的执行逻辑,但是这个步骤可以说是图形开发者最关心的部分。
这是UnrealEngine4 RenderGraph部分的大致执行逻辑:
FRDGBuilder graph(cmd_buf);
// Pass0,声明并添加Pass到rendergraph中,对应Declaration步骤
graph.add_pass(
...
[pass_0_params, shader_0](cmd_buf) {
... // 真正执行对应DrawCall或ComputeShader,对应Dispatch步骤
}
);
// Pass1,声明并添加Pass到rendergraph中,对应Declaration步骤
graph.add_pass(
...
[pass_1_params, shader_1](cmd_buf) {
... // 真正执行对应DrawCall或ComputeShader,对应Dispatch步骤
}
);
// rendergraph调用,对应Invocation步骤
graph.execute();
上述代码中Dispatch步骤是个lambdas表达式,当用户调用graph.execute()时,每个Pass的Dispatch步骤将开始执行,执行完成后当前Pass结束。
Lambdas表达式的用法比较倾向于在生命周期内进行快速但是较为松散的处理。不过有些语言对这种处理风格会比较严格。所以下述的写法可以作为Lambdas表达式写法的替代:
// Declaration(声明)阶段
let pass_0 = graph.add_pass(...);
let pass_1 = graph.add_pass(...);
graph.build();
// Invocation阶段
pass_0.begin();
... // 真正执行对应DrawCall或ComputeShader,对应Dispatch步骤
pass_0.end();
pass_1.begin();
... // 真正执行对应DrawCall或ComputeShader,对应Dispatch步骤
pass_1.end();
哪种写法比较好这里不做比较,一切的争执都是因为比较产生,放下争执。
可以简单剖析下它的具体实现(以Vulkan为例):
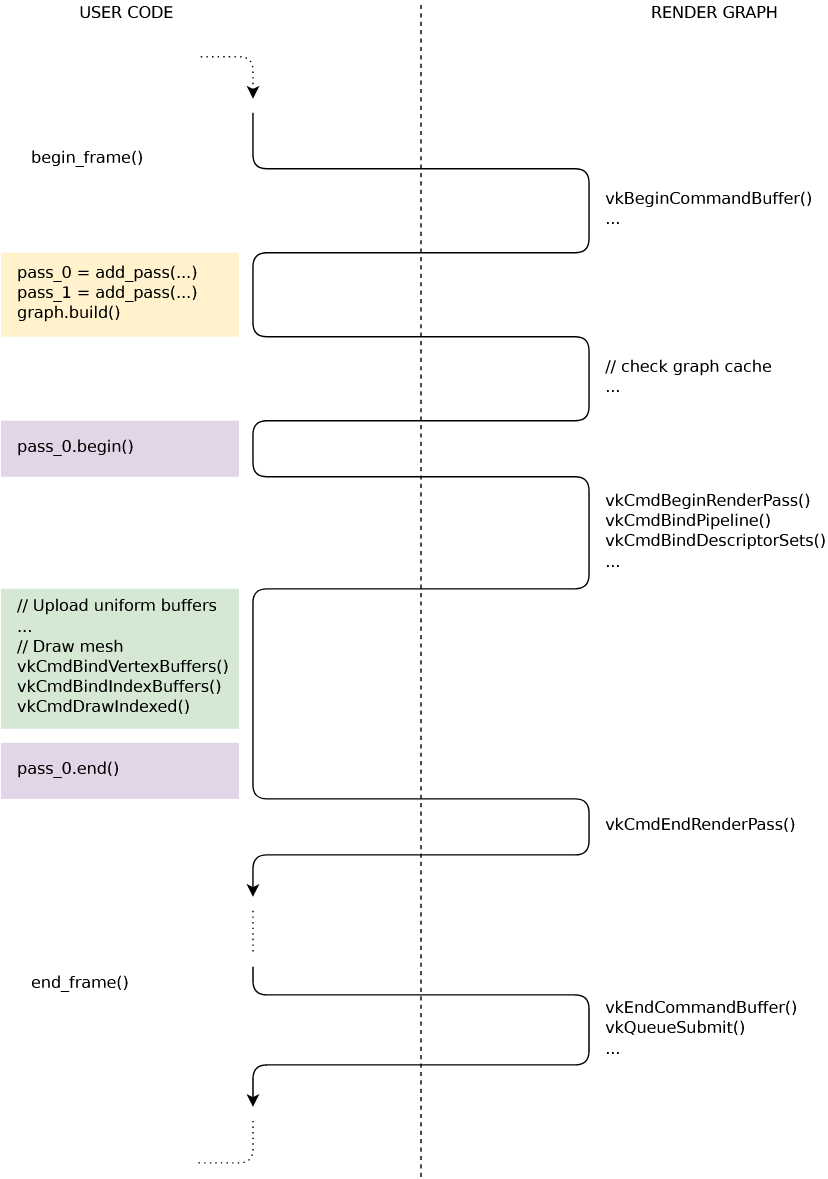
分割线左半部分为用户编写的RenderGraph调用,右半部分为在Vulkan中的具体实现
- begin_frame()函数会调用vkBeginCommandBuffer开启命令缓冲。
- 然后对RenderGraph进行声明。调用add_pass()函数对Pass进行添加,RenderGraph会将这些添加的Pass信息存储在一个内置的数组中。
- 当graph.build()函数被调用时,我们会对Pass数组进行哈希处理,并检查是否已经有一个具有相同哈希的GraphCache。如果没有,我们就构建一个新的。Graph的构建代价是很大的,所以一般只发生在应用程序启动时、窗口调整时、着色器热重载时,或者渲染逻辑改变时。
- pass.begin()和pass.end()两个函数在调用时会将RenderPass的指令和PipelineState的变化更新到CommandBuffer中,Pipeline barriers也可能会在这里插入。
- 真正的执行逻辑会在begin()与end()函数之间进行,比如通过vkCmdBindIndexBuffer绑定索引缓冲,通过vkCmdBindVertexBuffers绑定顶点缓冲,通过vkCmdDrawIndexed绘制IBO等。
- 最后,end_frame()调用vkEndCommandBuffer结束命令缓冲区并调用vkQueueSubmit()通知硬件队列提交数据。
整个RenderGraph的流程基本上是这样的。
可能有人会问,RenderGraph是不是FrameGraph:RenderGraph不等于FrameGraph, 可以简单的理解RenderGraph是对FrameGraph的进一步抽象,这是RenderGraph出处的解释:

本文参考:
- wihlidal-munich2018-halcyonvulkan
- Apoorva Joshi:RenderGraph
