粒子与3D公告板(billboards)非常相似,但有两大主要区别:
- 通常粒子的数量非常多。
- 粒子是动态的:
- 它们会移动。
- 它们会生成和消失。
- 它们通常是半透明的。
这些区别也带来了一些问题。本教程将介绍一种解决这些问题的方法;当然,还有许多其他可能的解决方案。
大量粒子的绘制
绘制大量粒子的第一个想法可能是使用之前教程中的代码,并为每个粒子调用一次 glDrawArrays。这是一个非常糟糕的想法,因为这意味着你强大的 GTX 512+ 多处理器将全部用于绘制一个四边形(显然,只有一个处理器会被使用,因此效率损失高达 99%)。然后你再绘制第二个公告板,情况也是一样的。
显然,我们需要一种能够同时绘制所有粒子的方法。
实现这一点的方法有很多,以下是其中三种:
- 生成一个包含所有粒子的单一 VBO:简单、有效,适用于所有平台。
- 使用几何着色器:不在本教程的讨论范围内,主要是因为 50% 的计算机不支持此功能。
- 使用实例化(Instancing:并非所有计算机都支持,但绝大多数都支持。
在本教程中,我们将使用第三种方法,因为它在性能和可用性之间提供了一个很好的平衡。此外,一旦这种方法实现,可以很容易地添加对第一种方法的支持。
实例化 (Instancing)
“实例化”意味着我们有一个基础网格(在我们的例子中,是一个由两个三角形组成的简单四边形),但这个四边形有多个实例。
技术实现
实例化是通过多个缓冲区来完成的:
- 一些缓冲区描述基础网格。
- 另一些缓冲区描述基础网格每个实例的特有属性。
对于每个缓冲区的内容,我们有很多选择。在我们这个简单的例子中,我们有以下内容:
- 一个用于网格顶点的缓冲区:没有索引缓冲区,因此它是 6 个
vec3,构成了 2 个三角形,进而组成了一个四边形。 - 一个用于粒子中心位置的缓冲区。
- 一个用于粒子颜色的缓冲区
这些是非常标准的缓冲区。它们的创建方式如下:
// 包含粒子的4个顶点的VBO(顶点缓冲区对象)。
// 由于使用了实例化技术,这些顶点将被所有粒子共享。
static const GLfloat g_vertex_buffer_data[] = {
-0.5f, -0.5f, 0.0f, // 左下角顶点
0.5f, -0.5f, 0.0f, // 右下角顶点
-0.5f, 0.5f, 0.0f, // 左上角顶点
0.5f, 0.5f, 0.0f, // 右上角顶点
};
GLuint billboard_vertex_buffer;
glGenBuffers(1, &billboard_vertex_buffer); // 生成VBO
glBindBuffer(GL_ARRAY_BUFFER, billboard_vertex_buffer); // 绑定VBO
glBufferData(GL_ARRAY_BUFFER, sizeof(g_vertex_buffer_data), g_vertex_buffer_data, GL_STATIC_DRAW); // 将顶点数据上传到GPU
// 包含粒子位置和数量的VBO
GLuint particles_position_buffer;
glGenBuffers(1, &particles_position_buffer); // 生成VBO
glBindBuffer(GL_ARRAY_BUFFER, particles_position_buffer); // 绑定VBO
// 初始化为空(NULL)缓冲区:它将在每帧中稍后更新。
glBufferData(GL_ARRAY_BUFFER, MaxParticles * 4 * sizeof(GLfloat), NULL, GL_STREAM_DRAW); // 分配内存但不填充数据
// 包含粒子颜色的VBO
GLuint particles_color_buffer;
glGenBuffers(1, &particles_color_buffer); // 生成VBO
glBindBuffer(GL_ARRAY_BUFFER, particles_color_buffer); // 绑定VBO
// 初始化为空(NULL)缓冲区:它将在每帧中稍后更新。
glBufferData(GL_ARRAY_BUFFER, MaxParticles * 4 * sizeof(GLubyte), NULL, GL_STREAM_DRAW); // 分配内存但不填充数据
和之前一样。它们的更新方式如下:
// 更新 OpenGL 用于渲染的缓冲区。
// 存在更复杂的方法可以将数据从 CPU 流式传输到 GPU,
// 但这些内容超出了本教程的范围。
// 参考链接:http://www.opengl.org/wiki/Buffer_Object_Streaming
glBindBuffer(GL_ARRAY_BUFFER, particles_position_buffer); // 绑定位置缓冲区
glBufferData(GL_ARRAY_BUFFER, MaxParticles * 4 * sizeof(GLfloat), NULL, GL_STREAM_DRAW); // 缓冲区孤 orphaning,这是一种提高流式传输性能的常见方法。详细信息请参见上述链接。
glBufferSubData(GL_ARRAY_BUFFER, 0, ParticlesCount * sizeof(GLfloat) * 4, g_particule_position_size_data); // 更新缓冲区子数据,写入粒子的位置和大小数据。
glBindBuffer(GL_ARRAY_BUFFER, particles_color_buffer); // 绑定颜色缓冲区
glBufferData(GL_ARRAY_BUFFER, MaxParticles * 4 * sizeof(GLubyte), NULL, GL_STREAM_DRAW); // 缓冲区孤 orphaning,这是一种提高流式传输性能的常见方法。详细信息请参见上述链接。
glBufferSubData(GL_ARRAY_BUFFER, 0, ParticlesCount * sizeof(GLubyte) * 4, g_particule_color_data); // 更新缓冲区子数据,写入粒子的颜色数据。
还是和往常一样。在渲染之前,它们以以下方式绑定:
// 第一个属性缓冲区:顶点
glEnableVertexAttribArray(0); // 启用顶点属性数组,索引为 0
glBindBuffer(GL_ARRAY_BUFFER, billboard_vertex_buffer); // 绑定包含四边形顶点的 VBO
glVertexAttribPointer(
0, // 属性索引。没有特别原因选择 0,但必须与着色器中的布局匹配。
3, // 每个顶点的数据大小(x, y, z)
GL_FLOAT, // 数据类型
GL_FALSE, // 是否归一化?
0, // 步幅(stride),即每个顶点之间的字节偏移量
(void*)0 // 缓冲区偏移量
);
// 第二个属性缓冲区:粒子中心的位置
glEnableVertexAttribArray(1); // 启用顶点属性数组,索引为 1
glBindBuffer(GL_ARRAY_BUFFER, particles_position_buffer); // 绑定包含粒子位置的 VBO
glVertexAttribPointer(
1, // 属性索引。没有特别原因选择 1,但必须与着色器中的布局匹配。
4, // 每个粒子的数据大小(x, y, z + size)=> 4
GL_FLOAT, // 数据类型
GL_FALSE, // 是否归一化?
0, // 步幅(stride)
(void*)0 // 缓冲区偏移量
);
// 第三个属性缓冲区:粒子的颜色
glEnableVertexAttribArray(2); // 启用顶点属性数组,索引为 2
glBindBuffer(GL_ARRAY_BUFFER, particles_color_buffer); // 绑定包含粒子颜色的 VBO
glVertexAttribPointer(
2, // 属性索引。没有特别原因选择 2,但必须与着色器中的布局匹配。
4, // 每个粒子的颜色数据大小(r, g, b, a)=> 4
GL_UNSIGNED_BYTE, // 数据类型
GL_TRUE, // 是否归一化?*** 是的,这意味着 unsigned char[4] 将在着色器中以 vec4(浮点数)形式访问 ***
0, // 步幅(stride)
(void*)0 // 缓冲区偏移量
);
这和往常一样。区别在于渲染时的操作。如果基础网格没有索引缓冲区,通常会使用 glDrawArrays;如果有索引缓冲区,则使用 glDrawElements。而现在,你会使用 glDrawArraysInstanced 或 glDrawElementsInstanced,这相当于调用 glDrawArrays N 次(N 是最后一个参数,在我们的例子中是 ParticlesCount):
glDrawArraysInstanced(GL_TRIANGLE_STRIP, 0, 4, ParticlesCount);
但这里还缺少一些东西。我们还没有告诉 OpenGL 哪个缓冲区是用于基础网格的,哪个缓冲区是用于不同实例的。这是通过 glVertexAttribDivisor 来完成的。以下是完整的带注释代码:
// 这些函数是专门为 `glDrawArrays*Instanced*` 设计的。
// 第一个参数是我们要设置的属性缓冲区。
// 第二个参数是“在渲染多个实例时,通用顶点属性更新的频率”。
// 参考链接:http://www.opengl.org/sdk/docs/man/xhtml/glVertexAttribDivisor.xml
glVertexAttribDivisor(0, 0); // 粒子顶点:始终重复使用相同的 4 个顶点 -> 更新频率为 0
glVertexAttribDivisor(1, 1); // 位置:每个四边形一个(粒子中心)-> 更新频率为 1
glVertexAttribDivisor(2, 1); // 颜色:每个四边形一个 -> 更新频率为 1
// 绘制粒子!
// 这里会多次绘制一个小的三角形带(看起来像一个四边形)。
// 它等价于以下代码:
// for(i in ParticlesCount) : glDrawArrays(GL_TRIANGLE_STRIP, 0, 4),
// 但效率更高。
glDrawArraysInstanced(GL_TRIANGLE_STRIP, 0, 4, ParticlesCount);
正如你所见,实例化非常灵活,因为你可以调整任意整数来作为 AttribDivisor 的参数。例如,使用 glVertexAttribDivisor(2, 10) 时,每 10 个连续的实例将具有相同的颜色。
重点是什么?
重点在于,现在我们每帧只需要更新一个小缓冲区(粒子的中心位置),而不需要更新一个巨大的网格。这带来了 4 倍的带宽节省!
生命周期
与场景中的大多数其他对象不同,粒子以非常高的频率创建和销毁。我们需要一种足够快速的方式来生成新粒子并移除旧粒子,而不是使用低效的方式如 "new Particle()"。
创建新粒子
为此,我们使用一个大的粒子容器:
// 粒子在 CPU 上的数据结构表示
struct Particle {
glm::vec3 pos, speed; // 位置和速度
unsigned char r, g, b, a; // 颜色 (红、绿、蓝、透明度)
float size, angle, weight; // 大小、角度、权重
float life; // 粒子的剩余生命周期。如果 < 0,则表示粒子已死亡且未被使用。
};
const int MaxParticles = 100000; // 最大粒子数量
Particle ParticlesContainer[MaxParticles]; // 粒子容器,用于存储所有粒子的数据
现在,我们需要一种创建新粒子的方法。这个函数会在 ParticlesContainer 中进行线性搜索,这听起来像是一个很糟糕的主意,但因为它从上次已知的位置开始搜索,所以这个函数通常会立即返回结果:
int LastUsedParticle = 0;
// 在 ParticlesContainer 中查找尚未使用的粒子。
// (即 life < 0 的粒子)
int FindUnusedParticle() {
// 从上次找到的粒子位置开始向后搜索
for (int i = LastUsedParticle; i < MaxParticles; i++) {
if (ParticlesContainer[i].life < 0) { // 如果找到一个未使用的粒子
LastUsedParticle = i; // 更新最后使用的粒子索引
return i; // 返回该粒子的索引
}
}
// 如果未在上述循环中找到,从数组开头继续搜索到 LastUsedParticle
for (int i = 0; i < LastUsedParticle; i++) {
if (ParticlesContainer[i].life < 0) { // 如果找到一个未使用的粒子
LastUsedParticle = i; // 更新最后使用的粒子索引
return i; // 返回该粒子的索引
}
}
return 0; // 如果所有粒子都在使用中,则覆盖第一个粒子
}
现在,我们可以用有趣的“生命周期”、“颜色”、“速度”和“位置”值来填充 ParticlesContainer[particleIndex]。具体的细节可以参考代码,但在这里你可以几乎做任何事情。唯一有趣的问题是,每帧应该生成多少个粒子?这主要取决于具体的应用场景,所以让我们假设每秒生成 10000 个新粒子(是的,这确实很多):
int newparticles = (int)(deltaTime*10000.0);
不过,你最好将这个数值限制在一个固定的范围内:
// 每毫秒生成 10 个新粒子,
// 但将此限制在 16 毫秒内(60 帧每秒),否则如果某一帧时间过长(例如 1 秒),
// 新生成的粒子数量会变得非常大,导致下一帧渲染时间更长。
int newparticles = (int)(deltaTime * 10000.0); // 根据 deltaTime 计算应生成的新粒子数
if (newparticles > (int)(0.016f * 10000.0)) // 限制最大生成量为 16 毫秒内的粒子数
newparticles = (int)(0.016f * 10000.0);
删除旧粒子
见下文。
主模拟循环
ParticlesContainer 包含了活跃与“消亡”的粒子,但是我们发送给 GPU 的缓冲区只需要包含那些仍然存活的粒子就行了。
因此,我们将遍历每个粒子,检查它是否还存活、是否应该消亡,如果一切正常,则添加一些重力效果,最后将粒子数据复制到一个专门用于 GPU 的缓冲区中。
// 模拟所有粒子
int ParticlesCount = 0; // 用于记录存活粒子的数量
for (int i = 0; i < MaxParticles; i++) {
Particle& p = ParticlesContainer[i]; // 粒子的快捷引用
if (p.life > 0.0f) { // 如果粒子还活着
// 减少粒子的生命值
p.life -= delta;
if (p.life > 0.0f) { // 如果粒子仍然活着
// 模拟简单的物理效果:仅考虑重力,忽略碰撞
p.speed += glm::vec3(0.0f, -9.81f, 0.0f) * (float)delta * 0.5f; // 添加重力影响
p.pos += p.speed * (float)delta; // 更新粒子位置
p.cameradistance = glm::length2(p.pos - CameraPosition); // 计算粒子与摄像机的距离平方
// 填充 GPU 缓冲区
g_particule_position_size_data[4 * ParticlesCount + 0] = p.pos.x; // 粒子位置 x
g_particule_position_size_data[4 * ParticlesCount + 1] = p.pos.y; // 粒子位置 y
g_particule_position_size_data[4 * ParticlesCount + 2] = p.pos.z; // 粒子位置 z
g_particule_position_size_data[4 * ParticlesCount + 3] = p.size; // 粒子大小
g_particule_color_data[4 * ParticlesCount + 0] = p.r; // 粒子颜色 r
g_particule_color_data[4 * ParticlesCount + 1] = p.g; // 粒子颜色 g
g_particule_color_data[4 * ParticlesCount + 2] = p.b; // 粒子颜色 b
g_particule_color_data[4 * ParticlesCount + 3] = p.a; // 粒子颜色 a
} else {
// 刚死亡的粒子将在 SortParticles() 中被移动到缓冲区的末尾
p.cameradistance = -1.0f; // 标记为死亡粒子
}
ParticlesCount++; // 只有活着的粒子才会增加计数
}
}
下图为输出结果,但是有些问题。。。:
排序
正如在教程 10 中所解释的,为了使混合效果正确,你需要将半透明对象从后到前进行排序。
void SortParticles(){
std::sort(&ParticlesContainer[0], &ParticlesContainer[MaxParticles]);
}
现在,std::sort 需要一个排序函数,用于确定容器中其中一个粒子应该放在另一个粒子的前面还是后面。这可以通过重载 Particle::operator< 来实现:
// CPU representation of a particle
struct Particle{
...
bool operator<(Particle& that){
// Sort in reverse order : far particles drawn first.
return this->cameradistance > that.cameradistance;
}
这将使得 ParticleContainer 得以正确排序,所以粒子现在能够正确显示了:
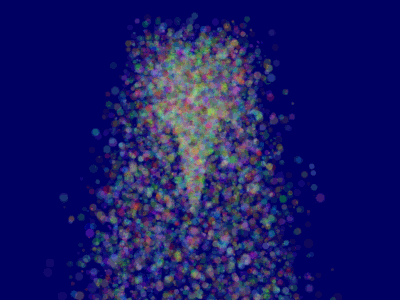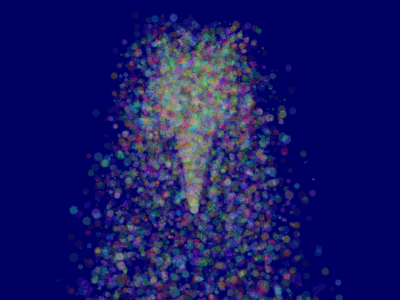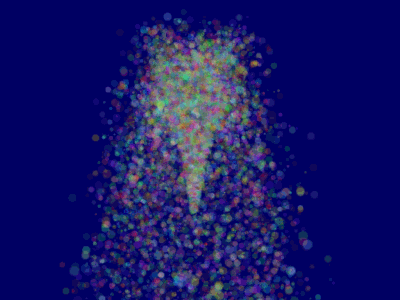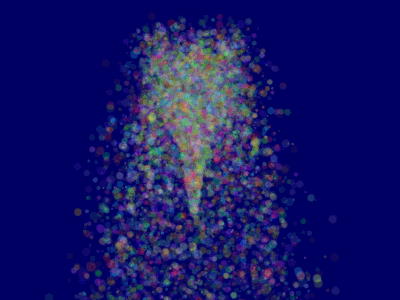
更进一步
粒子动画
你可以使用 纹理图集(Texture Atlas)来为粒子添加动画效果。在发送每个粒子的位置信息时,同时发送粒子的生命周期,然后在着色器中根据粒子的声明周期计算 UV 坐标,类似于我们在 2D 字体教程中所做的方式。一个纹理图集看起来像这样:

处理多个粒子系统
如果你需要的粒子系统不止一个,你可能有两种选择:使用统一的 ParticleContainer 或为每个粒子系统分别创建一个容器。
单一容器(适用于所有粒子)
优点:如果你为所有的粒子使用统一的容器,那么你可以完美地对它们进行排序。
缺点:你需要为所有粒子使用相同的纹理,这可能会是一个大问题。虽然可以通过使用纹理图集(将所有不同的纹理放在一个大纹理上,并使用不同的 UV 坐标)来解决这个问题,但编辑和使用这样的图集并不方便。
每个粒子系统一个容器
优点:如果为每个粒子系统分别创建容器,粒子只会在这个容器内部进行排序。这种方式更灵活,可以为每个粒子系统使用不同的纹理。
缺点:如果两个粒子系统发生重叠,可能会出现 视觉伪影(artefacts)。不过,如果你的应用需求对这种现象能接受,这也不是一个问题。
当然,你也可以设计一种混合系统,包含多个粒子系统,每个系统都有一个小而易于管理的纹理图集。
平滑粒子
你很快会注意到一个常见的视觉伪影:当粒子与某些几何体相交时,粒子的边界会变得非常明显且难看:

深度缓冲区测试与软粒子技术
一种常见的解决方法是检测当前正在绘制的片元是否接近 Z 缓冲区。如果是这样,就让该片元逐渐淡出(即降低其透明度)。
然而,为了采样 Z 缓冲区,普通的 Z 缓冲区无法直接使用。你需要将场景渲染到一个渲染目标中。或者,可以使用 glBlitFramebuffer 将 Z 缓冲区从一个帧缓冲区复制到另一个帧缓冲区。
参考文档:NVIDIA Soft Particles 技术白皮书
提高填充率(Fillrate)
在现代 GPU 中,填充率(Fillrate)是最重要的限制因素之一:它指的是 GPU 在每帧 16.6 毫秒(60 FPS)的时间内能够写入的片段(像素)数量。
因为粒子系统通常需要大量的填充率,所以这也会成为问题。例如,同一个片段可能会被多次重新绘制,每次用不同的粒子覆盖;如果不这样做,就会出现上述提到的视觉伪影。
在所有被写入的片段中,有很大一部分实际上是无用的,尤其是粒子边缘的部分。通常粒子纹理在边缘区域是完全透明的,但粒子的网格仍然会绘制这些部分,并且更新颜色缓冲区的值与之前绘制过程完全相同,所以造成了无用的浪费。
下面这个小工具可以计算出网格(即我们通过 glDrawArraysInstanced() 绘制的网格),使其紧密贴合你的纹理:
粒子物理
在某些情况下,我们可能希望粒子与游戏世界有更多的交互。例如,粒子可以在地面上反弹。
检测碰撞的方法
逐帧射线检测:
我们可以为每个粒子发射一条射线,从当前位置到目标位置之间进行检测。我们在拾取(Picking)教程中学过这种方法。然而,这种方法的计算成本极高,无法在每帧对每个粒子都执行射线检测。
近似几何体:
根据我们的应用需求,可以将场景中的几何体近似为一组平面,并仅在这组平面上进行射线检测。或者,可以使用真实的射线检测,但将结果缓存起来,并利用缓存来近似处理附近的碰撞(当然,也可以同时采用这两种方法)。
基于深度缓冲区的碰撞检测:
一种完全不同的技术是利用现有的 Z 缓冲区作为可见几何体的粗略近似,并让粒子与这个近似几何体发生碰撞。这种方法速度较快且“足够好”,但由于无法在 CPU 上快速访问 Z 缓冲区,因此所有的模拟必须在 GPU 上完成,这会使实现变得更加复杂。
相关资源链接
以下是一些关于这些技术的文章和资源:
- Hack Day Report 这篇文章讨论了一些与粒子系统和碰撞检测相关的技巧(链接貌似失效了)。
- GDC Vault - Chris Tchou’s Halo Reach Effects 这是一个关于《Halo Reach》中效果设计的技术分享,其中包括粒子系统与环境交互的实现细节。
通过这些资源,你可以更深入地了解如何优化粒子系统的物理交互和性能。
GPU 模拟
正如前面提到的,我们可以完全在 GPU 上模拟粒子的运动。不过,仍然需要在 CPU 上管理粒子的生命周期——至少是生成(spawn)粒子的部分。
实现这一目标的方法有很多,但这些内容超出了本教程的范围。这里仅提供一些指引:
使用 Transform Feedback
- Transform Feedback 允许将顶点着色器的输出存储在 GPU 端的 VBO(顶点缓冲区对象)中。可以将新位置存储在这个 VBO 中,下一帧时,使用这个 VBO 作为起点,并将新位置存储到原来的 VBO 中。
- 不使用 Transform Feedback 的方法。将粒子的位置编码到一个纹理中,并通过渲染到纹理(Render-To-Texture)的方式更新该纹理。
- 使用通用 GPU 库。使用 CUDA 或 OpenCL 等通用 GPU 库,它们提供了与 OpenGL 互操作的功能。
- 使用计算着色器(Compute Shader)。这是最简洁的解决方案,但仅在非常新的 GPU 上可用。
